行为实验任务常被视作客观、可控的心理测量工具,广泛应用于认知控制、发展心理、临床研究及神经影像等领域。然而,一个长期被忽视的问题是:许多经典范式(如Stroop任务、Flanker任务)在群体水平上表现出稳健的效应,但在个体水平的测量上却往往信度不佳。这一问题被称为“信度悖论”(reliability paradox),严重制约了行为任务在个体差异预测、临床筛查及纵向追踪等转化场景中的应用。
针对这一困境,pg电子app-pg电子app下载
社会心理学研究所党君华教授在国际心理学顶刊《认知科学趋势》(Trends in Cognitive Sciences)发表题为《预先设计优于事后可靠性修补》(Upfront Design Beats Post Hoc Reliability Fixes)的观点文章。该文系统梳理了提升行为任务个体测量信度的七类常见策略,并提出了一个关键论断:唯有从任务设计源头入手,增加个体内试次数或提升单试次信噪比,才能真正改善个体水平的信度;而事后统计修补手段(如扩大样本量、变换计分方式、采用计算模型或潜变量方法等)虽有助于群体推断或机制解释,却无法弥补已经采集的数据中试次噪声的损失。
文章首先建立了一个简洁的测量模型,将个体在某一任务上的表现分解为其真实稳定分数与试次噪声之和。由此推导出个体水平信度的决定因素:个体内试次数(L)和信噪比(γ⟡),设定:
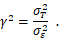
则信度:
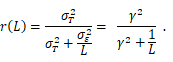
作者将既有策略归纳为七类,其中仅“增加试次数”和“任务校准”属于设计层面的源头干预,其余五类(增大样本量、更换计分指标、计算建模、多层次估计、潜变量建模)均为事后处理,无法改变已有数据中每个个体的试次噪声水平。文章引用了近期一项极端精度设计的实证研究:当个体完成数千次抑制控制任务试次后,信度随试次增加而上升,并在约1000试次后趋于稳定;而在试次数量有限的常规条件下,无论采用何种复杂的事后分析方法,个体信度始终维持在较低水平。这一结果强有力地表明,信度瓶颈主要源于数据采集阶段的测量工程问题,而非分析手段的不足。
在此基础上,作者提出了未来研究的三个方向:其一,系统评估常用行为任务的信噪比和达到不同信度目标所需的试次数量,并扩展至更广泛的任务类型(如N-back、任务转换等);其二,聚焦于提升单试次信息量的任务校准方法,如增加刺激复杂度、改变反应规则或引入跨通道冲突等;其三,建立公开的测量审计资源库,报告不同任务的“信度-试次”曲线、饱和点及针对不同研究目标所需的试次预算,以便研究者基于已知精度而非便利性选择任务。
文章最后指出,高信度是将认知任务视为有效测量工具的先决条件,算法创意应建立在测量工程的基础之上。同时,信度只是测量问题的一部分,未来研究还需检验经过校准的任务是否在收敛效度和真实世界预测力上表现更优。
简单来说,实验室常用的注意力或自控力测试在群体比较时很有效,但用于衡量具体个体能力差别时往往不可靠。本文指出,事后统计补救用处不大,真正关键的是在设计阶段就下功夫——这一结论为教育评估、临床筛查等领域的精准测量指明了方向。
《认知科学趋势》是认知科学领域最具影响力的国际期刊之一(2024年影响因子17.2),也是pg电子app-pg电子app下载
认定的最具国际影响力学术期刊之一,主要发表具有前沿性、启发性的观点综述与评论文章。党君华教授(pg电子app下载
青年拔尖A类人才,入选陕西省人才计划和美国心理协会学术新星)为本文第一和联合通讯作者,pg电子app-pg电子app下载
社会心理学研究所为第一通讯单位。该成果的发表彰显了西安交通大学在认知测量与方法论研究领域的国际学术影响力。
论文链接://www.sciencedirect.com/science/article/pii/S1364661326000811

